Track AI model executions with LangFuse observability for better performance insights
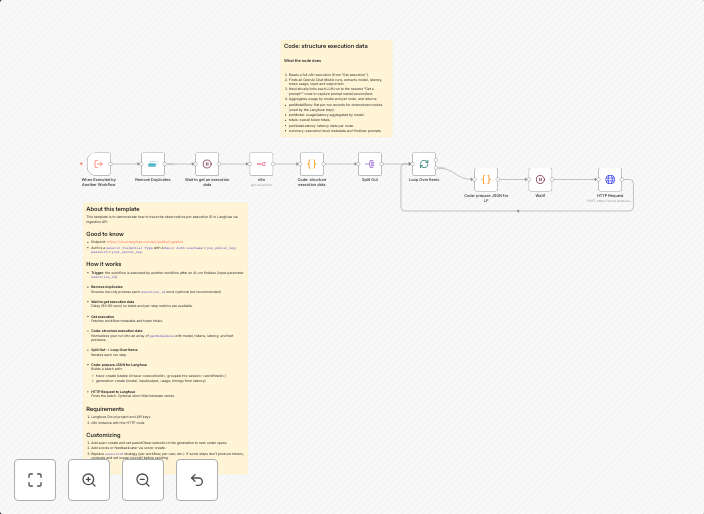
About this templateThis template is to demonstrate how to trace the observations per execution ID in Langfuse via ingestion API. Good to knowEndpoint:...
Get This WorkflowAbout This Workflow
Track AI model executions with LangFuse observability for better performance insights
This template automates the process of tracing observations per execution ID in LangFuse via the ingestion API, providing valuable insights into AI model performance. It enables real-time monitoring and analysis of model executions, helping to identify areas for improvement. By doing so, it improves the overall efficiency and effectiveness of AI model development.
This workflow is designed for developers and data scientists working with AI models, as well as engineers responsible for maintaining and optimizing AI infrastructure.
- Traces observations per execution ID in LangFuse via the ingestion API
- Provides real-time monitoring and analysis of AI model performance
- Enables identification of areas for improvement in AI model development
- Integrates with LangFuse to collect observability data
Import this workflow into your n8n instance and customize it according to your specific AI model and LangFuse setup. Configure the workflow to ingest data from your AI model executions and start tracking observations to gain valuable insights into your model's performance.
Use This Workflow in n8n →Similar Workflows
Affiliate Disclosure: We may earn a commission if you sign up for n8n through our links. This doesn't affect our recommendations.